视觉语言模型在许多多模态任务上表现强劲,但细粒度视觉推理仍然难以在可控、可复现的条件下被准确评估。 现有基准往往是静态的、依赖大量人工标注,且难以精细控制难度。MPF-Bench 提出了一个程序化生成的基准家族, 每个样本都由构造过程直接确定。
这种设计带来了确定性标签、精确评分、零标注成本,以及基于网格尺寸、候选数量和遮挡形状的难度控制。 同时,这种可验证结构也使 MPF 可以被复用于自监督训练信号,但基准评测仍然是它的首要目标。
ACM MM '26 数据集赛道投稿 · 项目主页
MPF-Bench 将自然图像重构为局部区域补全任务,具备确定性标签、精确打分、零人工标注成本, 并可通过网格尺寸、候选数量和遮挡形状系统性控制难度。
摘要
视觉语言模型在许多多模态任务上表现强劲,但细粒度视觉推理仍然难以在可控、可复现的条件下被准确评估。 现有基准往往是静态的、依赖大量人工标注,且难以精细控制难度。MPF-Bench 提出了一个程序化生成的基准家族, 每个样本都由构造过程直接确定。
这种设计带来了确定性标签、精确评分、零标注成本,以及基于网格尺寸、候选数量和遮挡形状的难度控制。 同时,这种可验证结构也使 MPF 可以被复用于自监督训练信号,但基准评测仍然是它的首要目标。
任务

传统 VQA 基准依赖人工标注,而 MPF-Bench 可以实现全自动数据生成、监督构造与评测。
“You are a professional image analysis expert. Given one masked image and its candidate patches,
select the single candidate that best fills the masked region. Judge continuity, texture, geometry,
color, and semantic plausibility. Return only the final patch index inside
<mpf> and </mpf>.”
基准家族
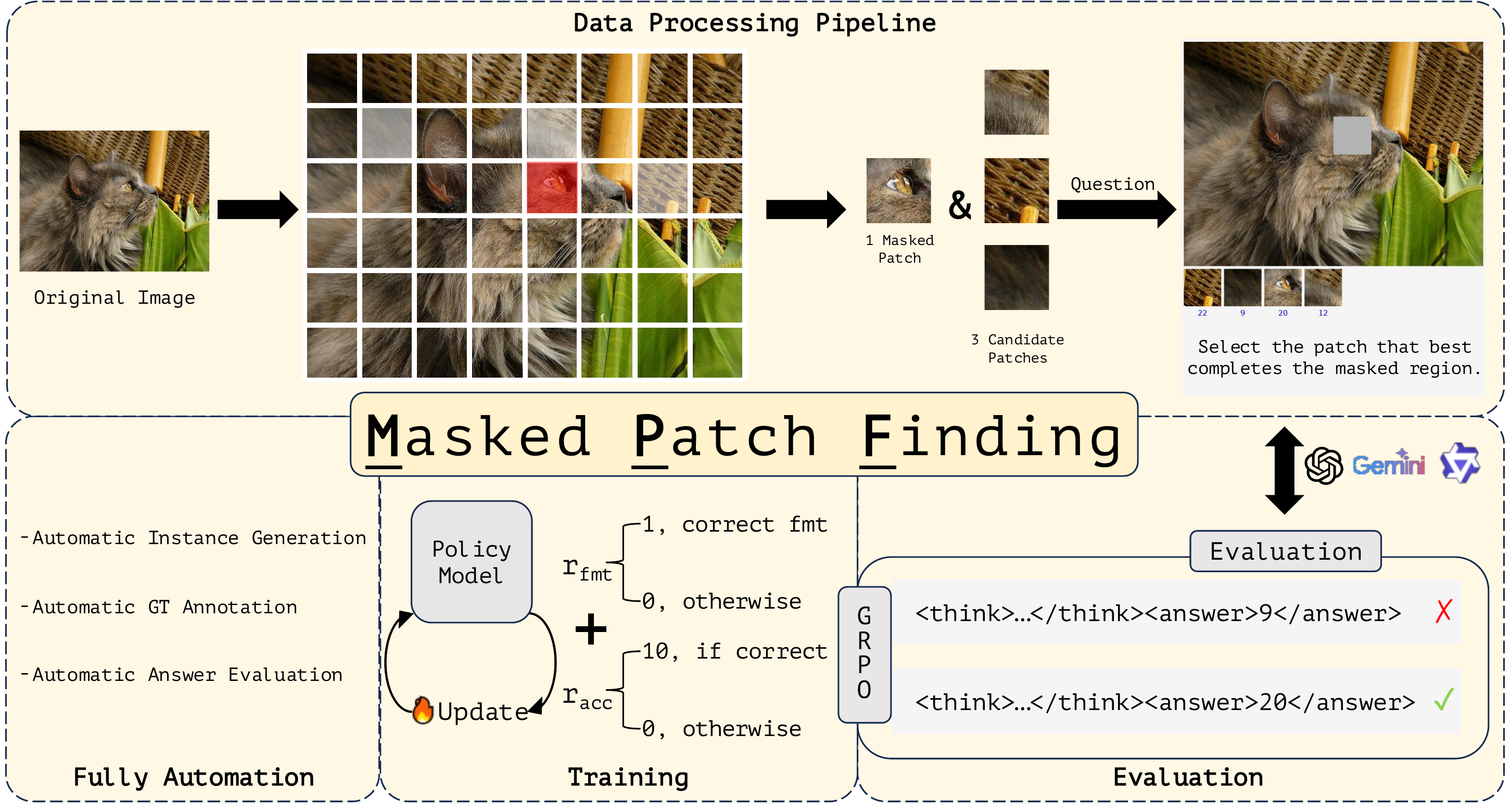
MPF-Bench 流水线概览。图 2 展示的是默认 `8×6`、`4-way` 设置下的 MPF 流程:MPF 自动生成推理样本、构建真值标签并完成模型评测。在实际构建流程中,会先过滤低信息量 patch,再从信息量排名靠前的 patch 中采样被遮挡目标,而不是对任意位置做均匀随机遮挡;同样的可验证结构也可复用于自监督训练。
在这一定义默认流程之外,发布版 MPF-Bench 还沿着下面三个可控配置维度进行变化。
`4×4`、`8×6`、`8×8` 与 `12×12` 控制局部上下文范围和 patch 粒度。
`4-way`、`8-way` 与 `16-way` 直接提升歧义度,也是最强的难度因素。
矩形与椭圆形遮挡会改变边界信息与局部连续性线索。

两种配置下的 MPF 样本示例。左图为 `12×12` 网格、16 个候选、矩形遮挡;右图为 `8×6` 网格、4 个候选、椭圆遮挡。
零样本结果
`12×12`、16-way、rect · 随机基线 `6.25%`
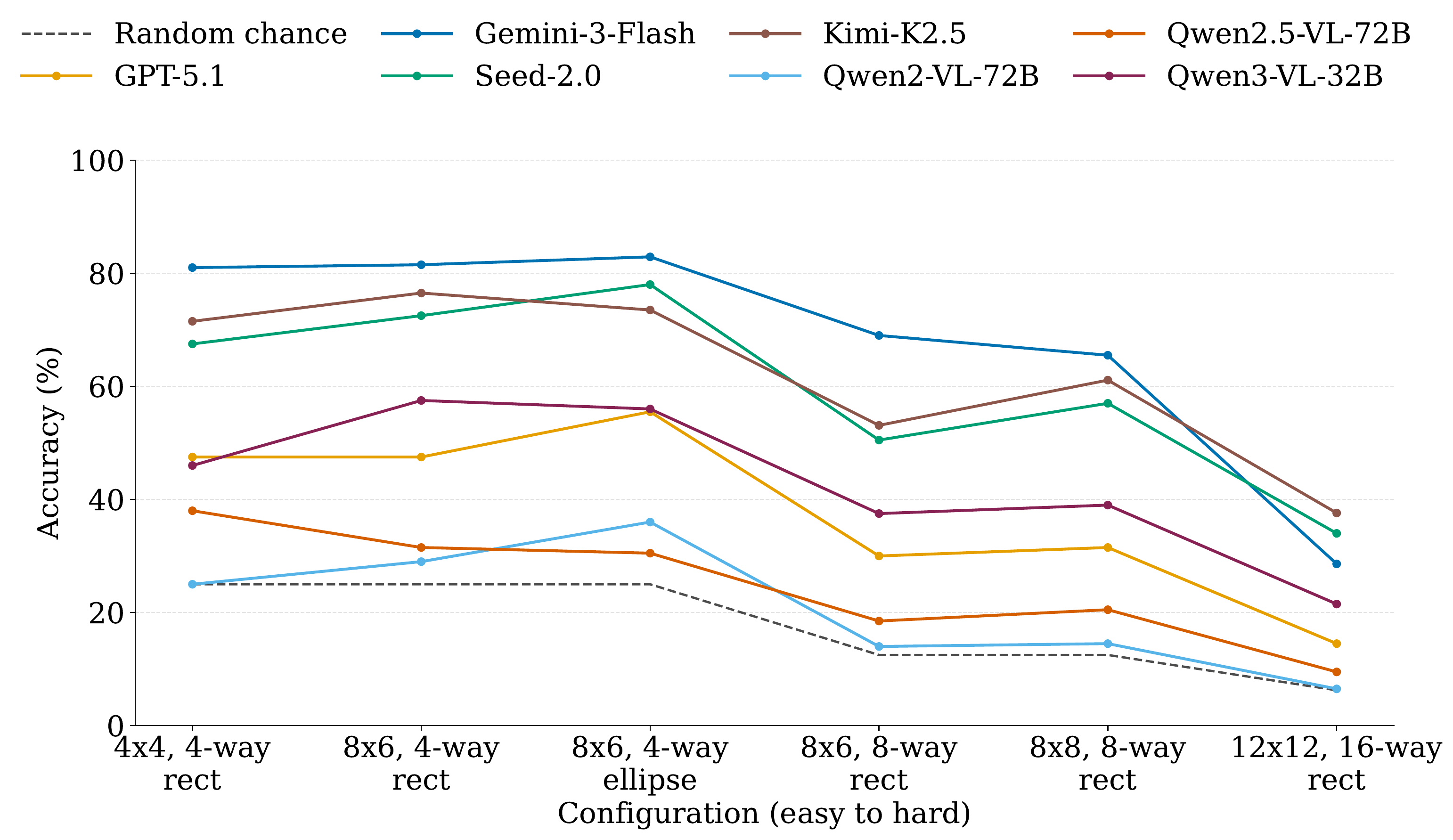
| 配置 | Qwen2-VL | Qwen2.5-VL | Qwen3-VL | GPT-5.1 | Seed-2.0 | Gemini-3-Flash | Kimi-K2.5 |
|---|---|---|---|---|---|---|---|
| `4×4`, 4-way, rect | 25.0 | 38.0 | 46.0 | 47.5 | 67.5 | 81.0 | 71.5 |
| `8×6`, 4-way, rect | 29.0 | 31.5 | 57.5 | 47.5 | 72.5 | 81.5 | 76.5 |
| `8×6`, 4-way, ellipse | 36.0 | 30.5 | 56.0 | 55.5 | 78.0 | 82.9 | 73.5 |
| `8×6`, 8-way, rect | 14.0 | 18.5 | 37.5 | 30.0 | 50.5 | 69.0 | 53.1 |
| `8×8`, 8-way, rect | 14.5 | 20.5 | 39.0 | 31.5 | 57.0 | 65.5 | 61.1 |
| `12×12`, 16-way, rect | 6.5 | 9.5 | 21.5 | 14.5 | 34.0 | 28.6 | 37.6 |
次要用途

| 模型 | MMBench | SEED-Bench | POPE | HallusionBench | MPF-Bench |
|---|---|---|---|---|---|
| Qwen2.5-VL-7B | 83.9 | 73.4 | 86.9 | 64.0 | 27.3 |
| Qwen2.5-VL-7B + MPF | 84.4 | 78.3 | 86.4 | 68.1 | 93.1 |
| InternVL3-1B | 57.6 | 69.4 | 83.9 | 47.5 | 21.6 |
| InternVL3-1B + MPF | 58.1 | 69.6 | 84.0 | 50.6 | 91.8 |
MPF 训练可以显著提升域内表现,但向外部多模态基准的迁移仍然相对有限。
讨论 / FAQ
这一部分用于澄清 MPF-Bench 的目标边界,并回答关于基准设计、构念有效性和训练用途的常见问题。 我们希望尽量明确地说明:MPF-Bench 在测什么、不声称测什么,以及为什么我们将训练定位为次要用途而非主要贡献。
MPF-Bench 的主要定位是一个 benchmark family。它的核心贡献是一个可程序化生成、可控且可精确验证的细粒度视觉推理评测框架。
我们额外研究了 MPF 作为自监督训练信号的用途,是因为同一任务结构天然提供了确定性奖励;但这部分只是附带研究,而不是论文的主张中心。
我们在协议设计上尽量减少与目标能力无关的干扰因素。所有模型接收的是同一张 composite image,具有相同布局和候选顺序,而不是依赖各家模型不同的 multi-image 接口。
同时,几乎所有设置下格式正确率都超过 99.5%,候选集外预测率低于 1%。这说明主要难点来自视觉歧义下的正确 patch 选择,而不是格式失败或无法理解指令。
8×6、4-way 或椭圆形遮挡这些设定?MPF-Bench 不是单一固定切片,而是一个 benchmark family。当前发布的基准沿三个显式难度维度变化:网格尺寸、候选数量和遮挡形状。
其中 8×6、4-way、矩形遮挡,只是训练实验中为了效率和可比性选用的工作配置,并不是整个 benchmark 的定义。
我们认为“既困难又可学习”本身是一个优点,而不是矛盾。零样本评测中,在最难的 12×12、16-way 设置上,若干强模型仍接近随机水平,说明更难切片远未饱和。
定向训练后在某个工作切片上获得高精度,说明任务是可学的;但这并不意味着整个 benchmark family 被做穿,因为仍然可以通过增加候选歧义和其他难度因素继续构造更难的切片。
MPF 更准确的目标是测量“受上下文约束的局部兼容性判断”,而不是脱离视觉上下文的“纯语义推理”。模型需要判断哪个候选 patch 在纹理、几何、颜色、材质和语义合理性上最符合周围区域。
为了减少过于简单的情况,流程会过滤低信息 patch,从空间上分离的区域采样 distractor,同时记录 distractor similarity 和 boundary ambiguity 等因素。我们并不声称完全消除了所有低层线索,但认为 MPF 提供了一个在受控歧义下、可扩展且可验证的细粒度局部推理压力测试。
我们有意将这部分表述为“中等提升”,而不是“普适提升”。这与我们的定位一致:MPF-Bench 首先是针对一种特定细粒度能力的评测工具,其次才是一个自监督训练信号。
强烈的域内提升说明任务是可学习且具有行为意义的;而外部 benchmark 上较温和的提升,则说明 MPF 捕捉的是多模态能力中的一个真实但相对狭窄的组成部分,而不是提升所有 benchmark 的通用配方。
引用
如果这个项目对你有帮助,可以使用下面的 BibTeX 条目进行引用。
@misc{zhu2026mpfbench,
title = {MPF-Bench: A Programmatically Verifiable Benchmark Family for Fine-Grained Visual Reasoning in VLMs},
author = {Xiuyuan Zhu and Ke Lu and Hao Wu and Zijin Du and Yuan Lei and Jian Xue},
year = {2026},
url = {https://xyzzzh.github.io/MPF-Bench/}
}